python sklern学习 波士顿房屋价格预测(线性回归)
本文共 4027 字,大约阅读时间需要 13 分钟。
单个特征的回归问题:
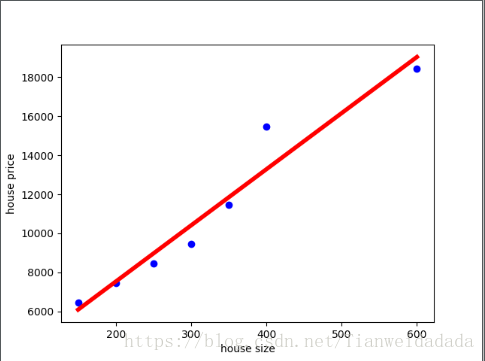
from sklearn import linear_modelimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom sklearn import datasets,linear_model#从csv文件读取数据的函数 ,这里直接用了数据,没有读取def get_data(file_name): data = pd.read_csv(file_name) X_parameter = [] Y_parameter = [] for single_square_feet ,single_price_value in zip(data['size'],data['price']): X_parameter.append([float(single_square_feet)]) Y_parameter.append(float(single_price_value)) return X_parameter,Y_parameter''' 构建一个 一size,price为列名的csv数据 数据转化为csv格式的方法 在dict中指出列名字'''#df = pd.DataFrame({'size':train_X,'price':train_y})#df.to_csv('C:/Users/zhangwei/Desktop/Machinelearning/house_price1.csv')''' 由于train_X是一个一唯的list(会被视为一个样本),需要转化为n_samples形式的二维形式 如果是在csv文件中,读取过程直接转化为此形式 也可以用np.array(train_X)把train转化为 此形式(此方法返回副本,重新赋值给train_X即可)'''#原始的X,y# train_y = [6450.0,7450.0,8450.0,9450.0,11450.0,15450.0,18450.0]# train_X = [150.00, 200.0, 250.0, 300.0, 350.0, 400.0, 600.0]# train_X = np.array(train_X).reshape(-1,1)# print(train_X)#从csv获取数据train_X,train_y = get_data('C:/Users/zhangwei/Desktop/Machinelearning/house_price1.csv')# print(train_X)# print(train_y)''' intercept:截距 coef:系数 predict_value:预测结果'''def get_predict(train_X,train_y,test_X): regr = linear_model.LinearRegression() regr.fit(train_X,train_y) predict_result = regr.predict(test_X) predict = {} predict['intercept'] = regr.intercept_ predict['coef'] = regr.coef_ predict['predict_value'] = predict_result return predict#对size == 700的房屋进行预测test_X = 700predict = get_predict(train_X,train_y,test_X)print("Intercept value :",predict['intercept'])print("coefficent :",predict['coef'])print('Predicted value:',predict['predict_value'])''' Intercept value : 1771.80851064 coefficent : [ 28.77659574] Predicted value: [ 21915.42553191]'''''' 绘制预测结果图'''def show_linear_result(train_X,train_y): regr = linear_model.LinearRegression() regr.fit(train_X,train_y) plt.scatter(train_X,train_y,color = "blue") plt.plot(train_X,regr.predict(train_X),color='red',linewidth=4) plt.xlabel('house size') plt.ylabel('house price') #plt.xticks(()) #plt.yticks(()) plt.show()show_linear_result(train_X,train_y) 预测结果:
参考:
两部电影预测观众喜好:
import csvimport sysimport matplotlib.pyplot as pltimport numpy as npimport pandas as pdfrom sklearn import datasets, linear_model# train_flash_X = [1,2,3,4,5,6,7,8,9]# train_flahs_y = [4.83,4.27,3.59,3.53,3.46,3.73,3.47,4.34,4.66]# train_arrow_X = [1,2,3,4,5,6,7,8,9]# train_arrow_y = [2.84,2.32,2.55,2.49,2.73,2.6,2.64,3.92,3.06]# df = pd.DataFrame({'flash_episod':train_flash_X,'flash_us_viewers':train_flahs_y,'arrow_episod':train_arrow_X,'arrow_us_viewers':train_arrow_y})# df.to_csv('C:/Users/zhangwei/Desktop/Machinelearning/TVshow.csv')# print(train_flash_X)# print(train_flahs_y)# print(train_arrow_X)# print(train_arrow_y)#def get_data(file_name): data = pd.read_csv(file_name) train_flash_X = [] train_flash_y = [] train_arrow_X = [] train_arrow_y = [] for x1,x2,x3,x4 in zip(data['flash_episod'],data['flash_us_viewers'],data['arrow_episod'],data['arrow_us_viewers']): train_flash_X.append([float(x1)]) train_flash_y.append([float(x2)]) train_arrow_X.append([float(x3)]) train_arrow_y.append([float(x4)]) return train_flash_X,train_flash_y,train_arrow_X,train_arrow_y#data = get_data('C:/Users/zhangwei/Desktop/Machinelearning/TVshow.csv')x1,y1,x2,y2 = get_data('C:/Users/zhangwei/Desktop/Machinelearning/TVshow.csv')def more_viewers(x1,y1,x2,y2): regr1 = linear_model.LinearRegression() regr1.fit(x1,y1) predict_value1 = regr1.predict(10) regr2 = linear_model.LinearRegression() regr2.fit(x2,y2) predict_value2 = regr2.predict(10) print(predict_value1) print(predict_value2) if predict_value1 > predict_value2: print('The Flash tv show will have more viewers for the next week~') else: print('The Tv show arrow will have more viewers for the next week~')more_viewers(x1,y1,x2,y2) 数据:
你可能感兴趣的文章
文件描述符
查看>>
终端驱动程序:几个简单例子
查看>>
HTML条件注释
查看>>
内核态与用户态
查看>>
趣链 BitXHub跨链平台 (4)跨链网关“初介绍”
查看>>
C++ 字符串string操作
查看>>
MySQL必知必会 -- 了解SQL和MySQL
查看>>
MySQL必知必会 -- 数据检索
查看>>
MySQL必知必会 -- 排序检索数据 ORDER BY
查看>>
POJ 3087 解题报告
查看>>
POJ 2536 解题报告
查看>>
POJ 1154 解题报告
查看>>
POJ 1661 解题报告
查看>>
POJ 1101 解题报告
查看>>
ACM POJ catalogues[转载]
查看>>
C/C++文件操作[转载]
查看>>
常见的排序算法
查看>>
hdu 3460 Ancient Printer(trie tree)
查看>>
KMP求前缀函数(next数组)
查看>>
KMP
查看>>